本地deepseek模型部署
2025年2月3日
一、安装ollama
- 第一种方式:(推荐)直接进入ollama官网 下载安装。
- 第二种方式:使用
docker安装。 参考 ollama官方docker镜像,需额外安装NVIDIA工具比较麻烦。 (需要注意的是,因为苹果电脑的虚拟化不支持GPU,所以只使用CPU推理,导致速度很慢,不建议docker安装。)
若下载很慢,注意科学上网
二、选择deepseek模型
- 在ollama官网点击
Models可查看所有直接安装的模型。 这里个人关注deepseek的3个模型,分别是deepseek-r1深度思考模型,去年出的deepseek-v3模型,以及deepseek-coder-v2模型。r1模型是最先进的,但是深度思考过程会导致出结果较慢(有时候看它的思考过程也是一种学习),所以如果问题不是特别复杂的我觉得还是使用v3模型就行。 而coder模型可以作为本地vscode + cline或者cursor的免费调用方案。 - 每个模型有不同大小,以
deepseek-r1举例,有1.5b、7b、8b、14b、32b、70b、671b。 每个模型后边的大小是模型占用磁盘大小,非运行需要的内存/显存大小。 小配置跑大模型不是不能跑,而是速度很慢。 这里参考建议是:8GB以下显存,使用1.5b模型,8GB显存使用7b或8b模型,12GB使用14b模型。再大就非普通个人电脑所能带动的了。 - 直接执行命令
ollama run deepseek-r1:8b,会下载对应的模型,并启动。 (输入/bye退出)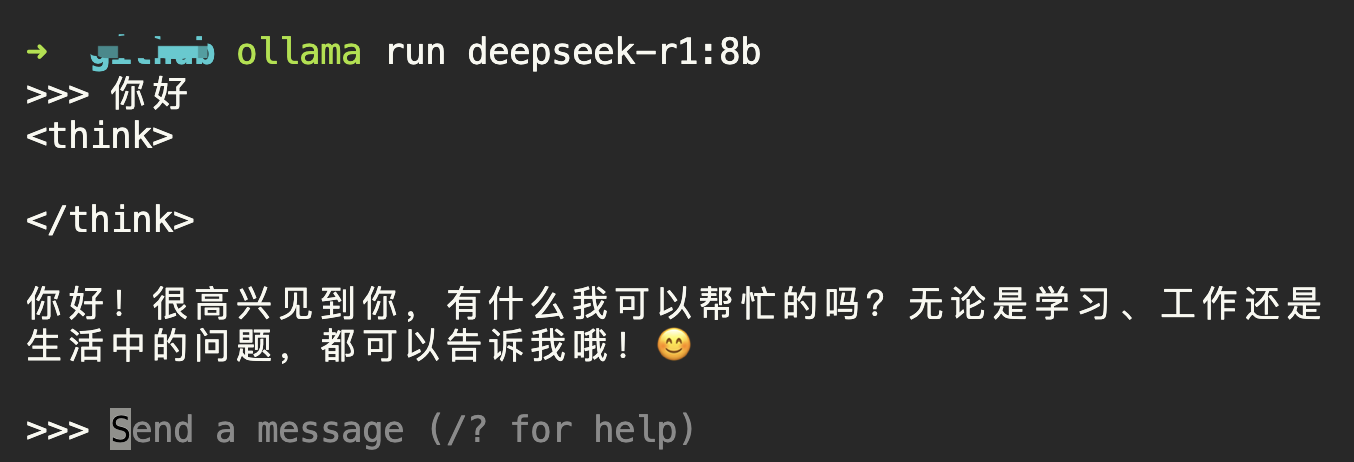
四、GUI界面
GUI的可选择性比较多,有 chatbox 、 open-webui、lobe 等,都支持远程密钥连接以及本地 ollama 连接